The following best practices for Amazon S3 can help prevent security incidents.
Disable access control lists (ACLs):
The provided information describes the concept of S3 Object Ownership in Amazon S3 and recommends disabling ACLs (Access Control Lists) for most use cases. Here are the key points from the information: S3 Object Ownership: S3 Object Ownership is a setting at the bucket level in Amazon S3 that allows you to control ownership of objects uploaded to your bucket and disable or enable ACLs. Default Setting: By default, Object Ownership is set to “Bucket owner enforced” and ACLs are disabled. This means that the bucket owner owns all the objects in the bucket and manages access to data using access management policies. Disabling ACLs: It is recommended to disable ACLs for most modern use cases, except for situations where you need to control access for each object individually. Access Control: When ACLs are disabled, access control for your data is based on policies such as AWS IAM user policies, S3 bucket policies, VPC endpoint policies, and AWS Organizations service control policies (SCPs). Simplified Permissions Management: Disabling ACLs simplifies permissions management and auditing. It allows access to be granted or denied based on policies rather than individual ACLs. Precautions before Disabling ACLs: Before disabling ACLs, you should review your bucket policy to ensure it covers all the intended ways of granting access to your bucket outside of your account. Also, reset your bucket ACL to the default (full control to the bucket owner). Behavior after Disabling ACLs: Once ACLs are disabled, your bucket will only accept PUT requests that do not specify an ACL or PUT requests with bucket owner full control ACLs. Other ACLs will fail, resulting in an HTTP status code 400 (Bad Request) with the error code AccessControlListNotSupported. For more detailed information and guidance on controlling object ownership and disabling ACLs in your bucket, you can refer to the Amazon S3 documentation, specifically the section titled “Controlling ownership of objects and disabling ACLs for your bucket” on page 674 of the Amazon Simple Storage Service User Guide.
Ensure that your Amazon S3 buckets use the correct policies and are not publicly accessible
The provided information highlights the importance of securing your S3 buckets and preventing public access. Here are the key points mentioned: S3 Block Public Access: Utilize S3 Block Public Access, which provides centralized controls to limit public access to your Amazon S3 resources. This helps ensure that even if resources are created in different ways, public access is restricted. You can refer to the documentation on “Blocking public access to your Amazon S3 storage” for more details. Review Bucket Policies and ACLs: Check your bucket policies and access control lists (ACLs) for any configurations that allow public access. Specifically, look for wildcard identities (“Principal”: “”), wildcard actions (“”), and permissions granted to “Everyone” or “Any authenticated AWS user”. Scan and Audit: Use the ListBuckets API operation to scan all your S3 buckets. Then, use GetBucketAcl, GetBucketWebsite, and GetBucketPolicy to evaluate the access controls and configurations of each bucket. AWS Trusted Advisor: Leverage AWS Trusted Advisor, a service that can inspect your Amazon S3 implementation and provide recommendations for securing your resources. Managed AWS Config Rules: Consider implementing ongoing detective controls by utilizing managed AWS Config Rules such as “s3-bucket-public-read-prohibited” and “s3-bucket-public-write-prohibited”. These rules help enforce restrictions on public read and write access to S3 buckets. By following these steps and implementing the recommended controls, you can enhance the security of your S3 buckets and prevent unauthorized public access to your data.
Implement least privilege access:
The information provided emphasizes the importance of implementing least privilege access when granting permissions in Amazon S3. Here are the key points mentioned: Amazon S3 Actions and Permissions Boundaries: Use Amazon S3 actions to enable specific actions that are required for performing tasks. Grant only the necessary permissions and avoid granting excessive privileges. Additionally, you can utilize IAM permissions boundaries to further restrict the maximum permissions that can be assigned to IAM entities. Bucket Policies and User Policies: Leverage bucket policies and user policies to control access to your S3 resources. These policies allow you to define granular permissions for specific buckets or individual users. By carefully crafting these policies, you can ensure that users have the minimum required permissions to perform their tasks. Access Control Lists (ACLs): Understand and utilize ACLs, which provide another level of access control for your S3 resources. ACLs can be used to grant permissions to specific AWS accounts or predefined groups of accounts. Service Control Policies (SCPs): Consider utilizing AWS Organizations’ Service Control Policies to manage and enforce permissions at the organizational level. SCPs allow you to set fine-grained permissions that apply across multiple AWS accounts within an organization. When implementing least privilege access, it is crucial to consider the specific requirements of your use case and grant permissions accordingly. By following these guidelines and leveraging the available mechanisms, you can minimize security risks and mitigate the potential impact of errors or malicious activities. For detailed guidance on access policy considerations, refer to the “Access policy guidelines” documentation.
Use IAM roles for applications and AWS services that require Amazon S3 access:
The best practice for granting applications running on Amazon EC2 or other AWS services access to Amazon S3 resources is to use IAM roles instead of storing AWS credentials directly in the application or EC2 instance. Here are the key points mentioned: IAM Roles: IAM roles are used to manage temporary credentials for applications or services that need access to Amazon S3. By assigning a role to an application or service, you don’t have to distribute long-term credentials such as access keys or passwords. The role provides temporary permissions that applications can use when making API requests to other AWS resources. Temporary Credentials: IAM roles provide temporary credentials that are automatically rotated, reducing the risk associated with long-term credentials. These temporary credentials have a limited lifespan and are automatically refreshed when they expire. Role-based Access Control: By using IAM roles, you can enforce fine-grained access control and assign specific permissions to applications or services. This allows you to follow the principle of least privilege, granting only the necessary permissions required for the application or service to function. To learn more about IAM roles and their usage in different scenarios, refer to the IAM User Guide, specifically the sections on IAM Roles and Common Scenarios for Roles: Users, Applications, and Services. By utilizing IAM roles, you enhance the security of your applications and services by eliminating the need to store long-term credentials and ensuring that access to Amazon S3 resources is controlled through temporary credentials with limited privileges.
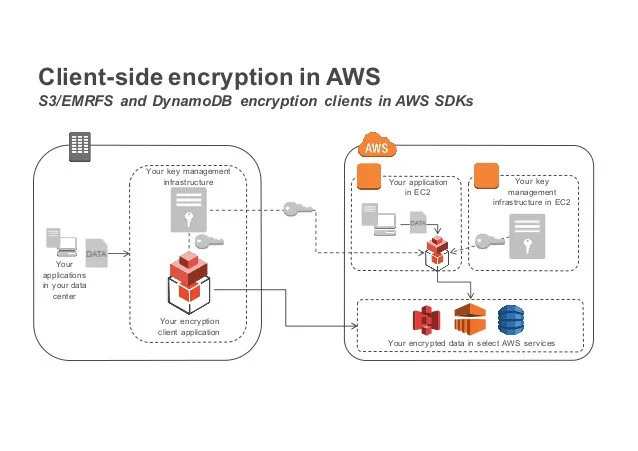
Consider encryption of data at rest:
To protect data at rest in Amazon S3, you have the following options: Server-side encryption: Amazon S3 provides server-side encryption options where the encryption is performed by Amazon S3 itself. a. Server-side encryption with Amazon S3 managed keys (SSE-S3): With SSE-S3, Amazon S3 automatically encrypts your objects using AES-256 encryption before storing them on disks. The encryption keys are managed by Amazon S3, ensuring a seamless encryption process without any additional effort from you. b. Server-side encryption with AWS Key Management Service (AWS KMS) keys (SSE-KMS): SSE-KMS allows you to leverage AWS Key Management Service to manage the encryption keys used for encrypting your objects. AWS KMS provides additional benefits such as centralized key management, key rotation, and auditing. c. Server-side encryption with customer-provided keys (SSE-C): SSE-C enables you to use your own encryption keys to encrypt the data before uploading it to Amazon S3. With SSE-C, you have full control over the encryption keys, but you are responsible for managing and protecting them. Client-side encryption: In client-side encryption, you encrypt the data on the client-side using encryption tools and techniques, and then upload the encrypted data to Amazon S3. With client-side encryption, you have full control over the encryption process and encryption keys. Amazon S3 provides various client-side encryption options, allowing you to choose the encryption tools and libraries that best suit your needs. By using server-side encryption or client-side encryption, you can ensure that your data is protected while at rest in Amazon S3. The choice between server-side encryption and client-side encryption depends on factors such as control over encryption keys, compliance requirements, and specific use cases. For more detailed information on protecting data with server-side encryption and client-side encryption in Amazon S3, refer to the respective sections in the Amazon S3 documentation.
Enforce encryption of data in transit:
To enhance the security of your Amazon S3 bucket, you can enforce the use of HTTPS (TLS) for all connections. This helps prevent eavesdropping and manipulation of network traffic by potential attackers. Here’s how you can enforce HTTPS (TLS) connections in Amazon S3: Update your Amazon S3 bucket policy: Modify your bucket policy to include the aws:SecureTransport condition, which allows access only over encrypted connections. This condition ensures that requests made to your bucket are accepted only if they are made using HTTPS. Here’s an example of a bucket policy that enforces HTTPS connections:
{
“Version”: “2012-10-17”,
“Statement”: [{
“Sid”: “EnforceHTTPS”,
“Effect”: “Deny”,
“Principal”: ““, “Action”: “s3:“,
“Resource”: “arn:aws:s3:::your-bucket-name/*”,
“Condition”: {
“Bool”: {
“aws:SecureTransport”: “false”
}
}
}
]}
Replace “your-bucket-name” with the name of your actual bucket. Implement AWS Config Rule: AWS Config provides managed rules that can help you maintain compliance and security. You can enable the s3-bucket-ssl-requests-only managed AWS Config rule. This rule checks if your S3 buckets accept only SSL requests and alerts you if any non-SSL requests are detected. Enabling this rule allows you to actively monitor and detect any attempts to access your S3 bucket over unencrypted connections. By enforcing HTTPS (TLS) connections and using AWS Config rules, you can ensure that all traffic to your Amazon S3 bucket is encrypted, minimizing the risk of unauthorized access or data interception.
Consider using S3 Object Lock:
S3 Object Lock is a feature in Amazon S3 that allows you to store objects using a “Write Once Read Many” (WORM) model. It helps prevent accidental or inappropriate deletion of data, ensuring that objects remain immutable and tamper-proof for a specified retention period. Here’s how S3 Object Lock works and how it can help protect your data: Enabling S3 Object Lock: To use S3 Object Lock, you first need to enable it at the bucket level. Once enabled, it applies to all objects within the bucket. Object Lock can be enabled either during bucket creation or by modifying the bucket properties. Object Lock Retention Modes: S3 Object Lock supports two retention modes: Governance Mode: In governance mode, you can specify a retention period during which an object cannot be deleted or modified. However, users with specific permissions can still overwrite retention settings or delete objects before the retention period expires.
Compliance Mode: In compliance mode, the retention period is set and cannot be overwritten or shortened by any user, including the root account. This provides stricter control over data immutability and ensures compliance with regulatory requirements.
Object Lock Protection: Once an object is locked using S3 Object Lock, it cannot be deleted or modified until the retention period expires. This protection applies to all users and accounts, including the root account. It helps prevent accidental deletions or unauthorized tampering of data, providing an additional layer of data protection. Use Cases: S3 Object Lock can be useful in various scenarios, such as: Protecting critical data: It can be used to store important records, audit logs, or compliance-related data that should be retained for a specific duration without modification or deletion.
Compliance requirements: It helps meet regulatory requirements for data retention and ensures data integrity by preventing unauthorized changes.
Legal and financial data: S3 Object Lock can be utilized to store legal documents, financial statements, or other sensitive data that must be preserved in an unaltered state for a specific period.
By leveraging S3 Object Lock, you can enforce a WORM model for your data, safeguarding it against accidental or malicious deletions and ensuring data integrity and compliance with regulatory standards.
Enable S3 Versioning:
S3 Versioning is a feature in Amazon S3 that allows you to keep multiple versions of an object within the same bucket. It provides a simple and efficient way to preserve, retrieve, and restore every version of every object stored in your bucket. Here’s how S3 Versioning works and how it can help you in data recovery and protection: Enabling Versioning: To use S3 Versioning, you need to enable it at the bucket level. Once enabled, S3 automatically assigns a unique version ID to each new object uploaded to the bucket. Previous versions of objects are retained, and you can access and restore them as needed. Preserving Object Versions: With S3 Versioning, every time you upload a new version of an object or modify an existing object, S3 creates a new version and retains the previous versions. This ensures that you have a complete history of changes made to the object over time. Retrieving Object Versions: You can retrieve specific versions of an object by specifying the version ID associated with that particular version. This allows you to access and restore previous versions of objects, providing a built-in backup and recovery mechanism. Protecting Against Unintended Actions: S3 Versioning helps protect your data from unintended user actions, such as accidental deletions or overwrites. Even if an object is deleted, the previous versions are still available and can be restored. Application Failure Recovery: In case of application failures or data corruption, S3 Versioning allows you to revert to a previous version of an object, ensuring that you can recover from such incidents without data loss. Ongoing Detective Controls: Implementing the “s3-bucket-versioning-enabled” managed AWS Config rule provides an ongoing detective control to ensure that versioning is enabled for your S3 buckets. This helps maintain consistency and adherence to your desired configuration. S3 Versioning provides a powerful mechanism for data recovery, protection against accidental changes, and maintaining a complete history of object versions. By enabling versioning and utilizing the available tools and controls, you can enhance the resilience of your data and easily recover from both user errors and application failures.
Consider using S3 Cross-Region Replication:
Amazon S3 Cross-Region Replication (CRR) is a feature that allows you to automatically replicate data between S3 buckets in different AWS Regions. It enables you to satisfy compliance requirements that dictate storing data at greater distances or in different geographical locations. Here’s how S3 Cross-Region Replication works and its benefits: Replicating Objects: With CRR, you can configure replication rules to automatically replicate objects from a source bucket in one AWS Region to a destination bucket in another AWS Region. The replication process is asynchronous, meaning that changes to objects in the source bucket are replicated to the destination bucket over time. Compliance and Data Residency: CRR is useful when compliance regulations require data to be stored in geographically diverse locations. By replicating objects across different AWS Regions, you can achieve additional data resilience and meet specific compliance requirements. Versioning Requirement: To use CRR, both the source and destination buckets must have versioning enabled. Versioning ensures that all versions of objects are retained and replicated appropriately. It allows you to access and restore previous versions of objects in the destination bucket. Data Transfer Efficiency: CRR optimizes data transfer by replicating only the changes made to objects. Once an object is replicated to the destination bucket, subsequent updates or modifications to the object are replicated incrementally. This minimizes bandwidth usage and replication time. Monitoring and Auditing: Enabling the “s3-bucket-replication-enabled” managed AWS Config rule provides ongoing detective controls to ensure that replication is enabled for your S3 buckets. This helps you maintain compliance and detect any misconfigurations or inconsistencies. S3 Cross-Region Replication provides a reliable and automated way to replicate objects across different AWS Regions, enhancing data resilience and meeting compliance requirements. By enabling replication and using the available monitoring and auditing tools, you can ensure that your data is replicated to the desired regions and maintain compliance with data residency regulations.
Consider using VPC endpoints for Amazon S3 access:
A Virtual Private Cloud (VPC) endpoint for Amazon S3 is a logical entity within a VPC that enables connectivity to Amazon S3 without traversing the open internet. It provides a private and secure channel for accessing Amazon S3 resources within your VPC. Here’s how VPC endpoints for Amazon S3 can help control access and enhance security: Restricted Connectivity: By using VPC endpoints, you can ensure that traffic between your VPC and Amazon S3 remains within the AWS network and doesn’t traverse the internet. This helps in preventing potential security risks and data exposure. Access Control with Bucket Policies: You can control the requests, users, or groups that are allowed to access your Amazon S3 data through a specific VPC endpoint by using S3 bucket policies. Bucket policies allow you to define granular access controls, specifying who can perform actions on your S3 buckets and objects. Restricting VPC Access: You can control which VPCs or VPC endpoints have access to your S3 buckets by using S3 bucket policies. This allows you to limit access to specific VPCs, ensuring that only authorized resources within those VPCs can interact with your S3 data. Data Exfiltration Prevention: By using a VPC that doesn’t have an internet gateway, you can prevent data exfiltration from your VPC to the internet. This further enhances the security of your S3 data by ensuring that it remains within the protected network environment. Implementing VPC endpoints for Amazon S3 provides a secure and controlled access mechanism for interacting with your S3 resources from within your VPC. By using S3 bucket policies and restricting VPC access, you can enforce fine-grained access controls and prevent unauthorized access to your data.
Use managed AWS security services to monitor data security:
AWS provides several managed security services that can help you identify, assess, and monitor security and compliance risks for your Amazon S3 data. These services offer automated detection, monitoring, and protection capabilities to safeguard your data. Here are some of the key managed AWS security services: AWS CloudTrail: CloudTrail provides comprehensive auditing and monitoring of your AWS account activity. It records API calls and events related to your S3 resources, allowing you to track changes, detect suspicious activities, and investigate security incidents. Amazon Macie: Macie is a security service that uses machine learning to automatically discover, classify, and protect sensitive data stored in S3. It helps you identify data exposures, enforce data privacy policies, and detect unusual access patterns to protect your data. Amazon GuardDuty: GuardDuty is a threat detection service that continuously monitors for malicious activities and unauthorized behavior within your AWS environment. It can analyze S3 access patterns and detect anomalies, compromised credentials, and data exfiltration attempts. Amazon Inspector: Inspector helps you assess the security and compliance of your AWS resources, including S3 buckets. It performs automated security assessments, identifies vulnerabilities, and provides detailed findings and recommendations to enhance the security posture of your S3 data. AWS Config: Config is a service that enables you to assess, audit, and evaluate the configuration of your AWS resources, including S3. It can help you monitor and enforce compliance requirements, detect unauthorized changes, and maintain a consistent and secure configuration for your S3 buckets. These managed AWS security services offer a range of capabilities to enhance the security of your Amazon S3 data. They provide automated monitoring, detection of security risks and vulnerabilities, and proactive protection measures. By leveraging these services, you can strengthen the security posture of your S3 resources and ensure compliance with industry regulations.